『またぞろ。』の掲載順位調査(最終)
『またぞろ。』の掲載順位についての調査の見直し。
・目的
またぞらーの茶番の民です。
『またぞろ。』がアニメ化するのか3乙するのか4乙するのか気になるので以前別の記事で調べてみましたが、結果的に3巻で完結しました。
なお、統計は相変わらずよくわかりませんが、掲載順が最終まで見えたので再度記事にしました。
・調査方法
前回記事と同一のプログラムで集計後、エクセルで整形しました。
・調査結果
非アニメ化3巻以上完結について
きららキャラットでアニメ化にはならず3巻以降で完結した作品の最終12話と現在の『またぞろ。』の掲載順を抽出したところ下記の表となりました。

結果的に、『またぞろ。』の平均順位数は前回より上がり8.3となり、他の作品より4.9ほど高い結果になりました。
また、センターカラー数も前回から増加し5となり、平均の倍となっています。
他の要因を調査
順位は良いのになぜ3巻で終わったか理由がないかを見ていたところ、以下の2つが思いつきました。
・掲載再作品数
きららキャラットはここ5年ほどで25作載っていたのが20作ほどに減っています。(図ー最終回の掲載作品数列参照)
そのため、掲載作品数に対してどれくらいの割合の位置に掲載しているかも調査してみました。(図ー掲載順位の割合列参照)
結果的に『すわっぷすわっぷ』に近い数値でしたがそれでも最も良い数値ではありました。
・アニメ化作品数
数年前はきららキャラットはアニメ化作品だらけだった気がしたので、その時期に連載が継続していたアニメ化作品数も調べてみました。図ーアニメ化作品の掲載数列参照)
ここでは、アニメ化作品数が2016年代は8、2019年代は10と現在の5に比べて多くなっていました。他作品はアニメ化作品が上位に来て、掲載順位が下がっていた可能性はありそうです。
・結論
以下のことが言えそうな気がしました。
・昔より掲載作品数が減っているので、掲載順位が良さそうでも案外3巻で終わったりする。
・アニメ化作品数で掲載順位が左右されがちのため、アニメ化作品数が少ないときは掲載順位が高めでも完結しやすい。
→現在のキャラットにおいては、『またぞろ。』ほどの掲載順位、カラー数でも3巻で終わる可能性が高そう。
・感想
掲載作品数が減っているというのを調査を通じて気が付きましたが、その分連載継続も厳しくなりそうでなかなかつらいところがあります。
幌田先生の次回作を期待しております。
まんがタイムきららキャラットの掲載順位に基づいた『またぞろ。』のアニメ化実現可能性および3巻乙の可能性の調査について
『またぞろ。』はアニメ化するのかどうか
・目的
またぞらーの茶番の民です。
『またぞろ。』がアニメ化するのか3乙するのか4乙するのか気になるので調べてみました。
なお、統計はよくわからず、結果的にアニメ化するかはよくわかりませんでしたに帰結しました。3乙はなさそうな傾向が見えました。
・先行研究について
きらら系列の掲載順位についての先行研究では下記サイト「四コマの調べ屋」がありました。このサイトでは掲載順位に基づき、2巻乙か3巻以上になるかを調査しているようです。
しかし、アニメ化についてや3巻以降の完結については調査が見つからなかったので今回は独自に調査を進めるところです。
また、きららサーチでは作品名や著者名などで検索が可能であり、作品の順位をすぐ調べたいときなどはとても役立ちます。
・調査方法
今回はきららキャラットの掲載順やカラー回数などをエクセルで一覧化し調査をおこなました。
まず、掲載順とカラー回数の抽出には先行研究がありましたので、下記のサイトを参考にしました。
上記サイトのソースからセンターカラーでの掲載号の記載、抽出対象作品の変更、CSV出力への変更などを行い抽出しました。
ソースとcsvは下記に格納しております。
その後抽出したデータをエクセルで整形し調査を行いました。
なお、掲載順の調査範囲としては昔過ぎても情勢が変わっていると考えたため、2013年1月号以降を対象としています。
・調査結果
アニメ化について
2013年以後のきららキャラットのアニメ化作品のアニメ化決定直近12話と、現在の『またぞろ。』の掲載順を抽出したところ下記の表となりました。
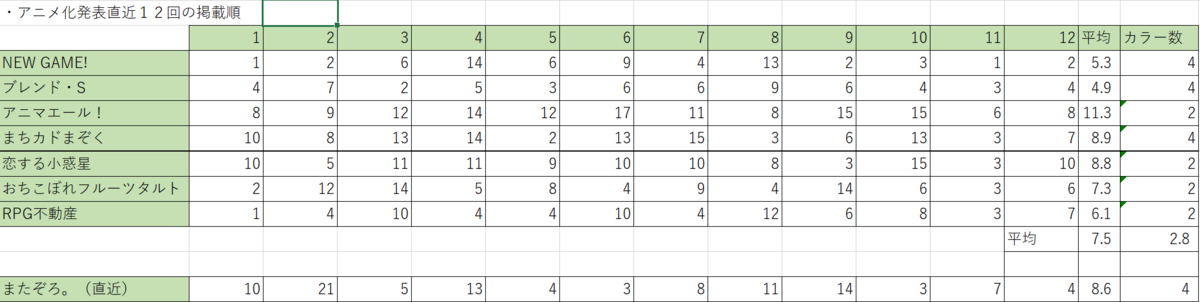
これを見ると、『またぞろ。』の掲載順はアニメ化作品の平均よりやや低いですがカラー数は多いことが見受けられます。また、『まちカドまぞく』や『恋する小惑星』の数値とほぼ同等であるためアニメ化の可能性は十分ありそうです。
3巻乙について
きららキャラットでアニメ化にはならず3巻以降で完結した作品の最終12話と現在の『またぞろ。』の掲載順を抽出したところ下記の表となりました。
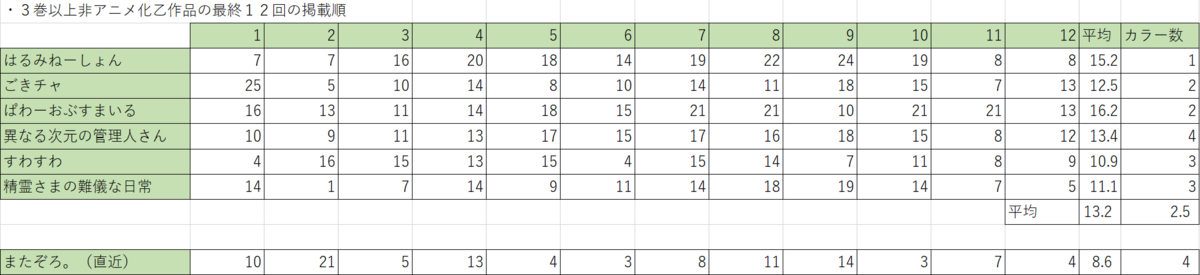
この表では、平均の掲載順が『またぞろ。』のほうが4.6ほど高くなっており、カラー数も多くなっています。最も掲載順が良かった『すわっぷ⇔すわっぷ』でも10.9でありまたぞろより。2.3低いため、この数値から考えると『またぞろ。』の3巻での完結はあまりなさそうと思われます。
3巻以降で完結した作品の最大値について
きららキャラットでアニメ化にはならず3巻以降で完結した作品の12話での平均掲載順位の最高区間と現在の『またぞろ。』の掲載順を抽出したところ下記の表となりました。
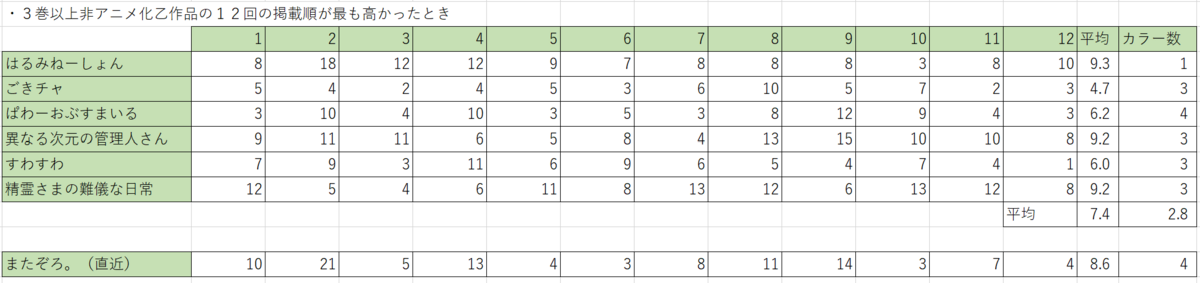
なお、アニメ化作品のアニメ化決定直近12話はこちらです。
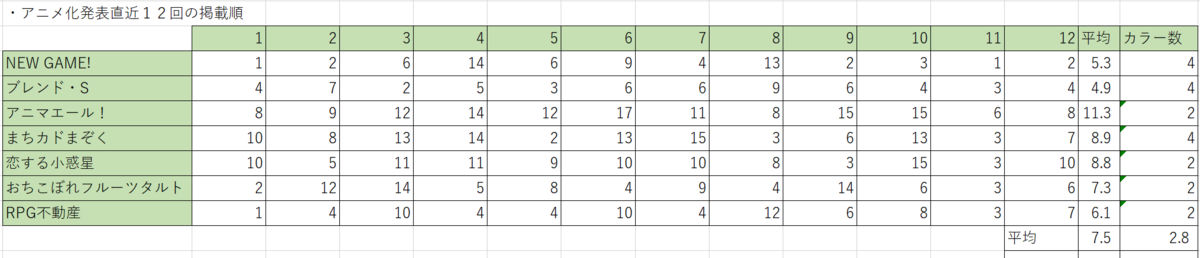
上記の表からすると、3巻以上でアニメ化せずに完結した作品はアニメ化直近12回とほぼ同等の掲載順位を経験していることがわかります。『ごきチャ』に至ってはアニメ化直近12話で最大の『ブレンド・S』より高い掲載順位でした。
・結論
以下のことが言えそうです。
・『またぞろ。』はアニメ化した作品との掲載順にそう差がないのでアニメ化する可能性は十分ある。
・『またぞろ。』非アニメ化の3巻以降の終了作の最終12話より掲載順が高いので3巻での完結はなさそうな気がする。
・アニメ化しなかった3巻以降終了作でもアニメ化直近12話と同等の掲載順位は経験するが、そのうち掲載順が落ちて完結になる。
→『またぞろ。』は現在の順位が続くうちはアニメ化の期待ができるが、順位が落ちてくると終わりが来そう。
・当調査の課題
・2013年~2019年頃のキャラットは25作掲載していたが直近は20作。単純に順位数だけで計算してよかったか
・アニメ化作品数の違い
2018年6月号はアニメ化作品が10作載っていた。直近の2023年3月号は4作とアニメ化作品の掲載数が倍以上違う
・余談
『またぞろ。』以外でも、キャラットで掲載中の2巻突破作品は3つほどありますがそれらとの比較がこちら。

どれも『またぞろ。』より掲載順位が良いので、アニメ化もあるのでしょうか。
ゆゆ式の特典確認の自動化について
この記事はゆゆ式Advent Calender 10日目の記事です。https://t.co/1JD2xTax2Y
#ゆゆ式ac
○ゆゆ式の特典確認の自動化について
・目的
ゆゆ式の単行本特典をpythonで自動確認しようというものです。(今となってはほぼ不要なものですが…)
なお、筆者は仕事でPythonを扱ったりしているわけではなくほぼ素人のコードになりますのでコードがアレなのはご了承ください。(一応動きました。)
・経緯
ゆゆ式の単行本はいまでこそきらら公式ツイッターで特典が公開されていますが、数年前までは公式告知がなく、作者の方が告知するなり読者が自分で各店舗のサイトを見て調べるなどしていた時代がありました。
過去に自分で調べてこんな画像を作ったりもしてました。

そこで、当時は自力で手動で確認していたわけですが、毎日各店舗のサイトを確認するのもなかなか面倒という問題がありました。というわけでプログラムで定期実行して楽をしたいという思いがありました。今となっては不要ですが、作れそうなので作ってみたところです。
・自動化概要
必要な要素として下記の点を満たしているものを考えました。
①単行本の作品ページのデータを取得し、特典について前回実行分と差分があるか判別する。差分は特典内容に対する更新のみであることを判別できるようにする。
②差分があった際に通知をする。(今回はデスクトップ通知とディスコード通知にしましたが、ラインとかメールとかも可能なようです。)
③上記①、②を数時間おきなどで定期実行する
③についてはSchedule文でも数時間おきに実行することは可能なようですが、今回はタスクスケジューラーを使って比較的簡単に済みましたのでそちらを使いました。というわけで①、②についてプログラムを作成しました。
・前提事項
下記のプログラムを使用する場合、Pythonの導入が必要になりますがそこから説明すると長くなりすぎてどうしようもないので割愛します。
ググれば出てくるものとは思いますが、私は初めてPythonを使ったときはこちらの本を参考にしました。Pythonの導入、エディタの導入、基本的な使い方からwebスクレイピングまで載っているので初心者の方には良いかもです。(某所のステマ)
次に、定期実行にするには実行場所として下記のようなものがあると思います。
①家のPCを起動し続ける
②Herokuなどクラウドを使う
③サーバーを借りる
私は①は電気代の問題と耐久面の不安、夜にうるさいなどの理由から避け、②のHerokuはCSVファイルの格納や指定がよくわからず、googleは金額計算のサイトが英語で読めずに怖かったため、③としてさくらのwindowsのVPSサーバーを使用しました。(レンタルサーバーではPythonが上手く動かない問題があったためVPSサーバーを使用)
・ソース
なお、今回はゲーマーズでの確認用です。抽出箇所が異なるため、htmlを確認するなどして店舗ごとに調整が必要になります。
import requests import difflib import datetime import os import re from discordwebhook import Discord from bs4 import BeautifulSoup from plyer import notification #ファイルの格納先 dir_path =r'E:\ドキュメント\surasura-python\tokuten' #前回取得ファイル file1_name = "gemazu1.csv" #今回取得ファイル file2_name = "gemazu2.csv" #店名を指定 tenmei="ゲーマーズ" #ここに対象のページのアドレスを入力 result = requests.get('****************') soup = BeautifulSoup(result.text,'html.parser') #スクレイピングの抽出対象を指定 html_list =soup.find_all(id=re.compile("tokuten")) ##ここから上は修正要 #今回分をgemazu2に保存し、前回と差分があれば報告してgemazu1を同内容で更新する #取得した内容をファイル2(今回分)に取得内容を記載 with open(file2_name,'w')as f: for html in html_list: okikae = html.get_text() naiyou = okikae.replace('\xa0','') f.write(naiyou) #パスを記載 file1_path = os.path.join(dir_path, file1_name) file2_path = os.path.join(dir_path, file2_name) #更新無しで初期化 kousin="nasi" #ファイル1があれば2と比較をする。なければ新規作成して終了。 if os.path.isfile(file1_path): file1 = open(file1_path) file2 = open(file2_path) #diffを定義 diff = difflib.Differ() #差分を抽出 output_diff = diff.compare(file1.readlines(), file2.readlines()) #差分箇所があれば更新ありフラグを立てる for data in output_diff : if data[0:1] in ['+', '-'] : kousin="ari" print(data) file1.close() file2.close() #ファイル1(前回分)に今回取得内容を記載 with open(file1_name,'w')as f: for html in html_list: okikae = html.get_text() naiyou = okikae.replace('\xa0','') f.write(naiyou) #デスクトップ通知とディスコード通知 if kousin == "ari": print(data) notification.notify( title = "ゆゆ式", message=tenmei+"特典更新あり", timeout=10 ) discord = Discord(url="*******************") discord.post(content=tenmei+"特典が更新されました。") else: print("なし")
・出力の想定
(1)基本的に各種作品ページは特典がある場合以下のように推移する。
①→②、②→③の場合にのみ通知を出力することとする。
①作品ページ作成時:この時点では特典情報の欄がないことが多い。
②特典種別掲載時:ここで、「クリアファイル」、「ブックカバー」など種別が表示される。ただし、特典画像は載っておらず「Now Printing」などが表示されていたりしている。
③特典画像掲載時:画像が掲載される。
(2)通知方法
外出時でも確認できるように更新の通知はディスコード通知でスマホにプッシュ通知が届くようにする。
・結果
ゆゆ式では確認できていませんが、他作品でテストしたところ動作は問題ありませんでした。特典部分が変わるとディスコードに通知が来るので家の外にいてもスマホで更新の確認ができそうです。サーバーで定期実行をすれば定期的に確認可能です。
これで次回以降は特典確認が楽にできますね。(まあ、もう公式告知があるのでほぼ不要なんですが…いい時代です。)
・課題
今後の課題点として以下のような点があります。
・抽出箇所の選定問題
html_list =soup.find_all(id=re.compile("tokuten"))の箇所になりますが、サイトごとに構成が違うため、メロンブックスやとらのあななど店舗ごとに抽出箇所を調べて変更する必要が出てくる。→各店舗分の作成が必要
また、サイトが改修された場合も抽出箇所を変えないといけない場合もある。
→巻が変わるごとに正常に動作するか確認が必要
・そもそも特典のある店舗がどこなのかという問題
正直わからないので前巻で出た店舗を調べるなり、他作品を参考に推測で進めるしかない。
・外出時の確認の際に結果的にサイトを見に行く必要がある
上記ソースでは画像が抽出されていないので、どういった画像なのか確認するにはそのページを見に行かなくてはならない。画像が貼られてる場合はその画像を貼れるようにするように調整したい。
・活用法について
きらら公式で告知されるのでだいたい不要なんですが、ざっと思いつく限りでは以下があります。
・メロンブックスでは過去に連動特典として他の巻と一緒に買うと特典が付く場合があった。公式で告知されないそういった更新をを読み取ることができる。
・公式告知より早く特典内容を知ることができる。
などでしょうか。
・まとめ
ゆゆ式の特典確認の自動化としては一定程度可能になりましたが、機能面で足りていない部分や各店舗対応などがまだ必要になりそうです。
また、可能であれば今後考察に生かせるプログラムかなにかを作れたらと思いました。(まあ、Pythonよくわからんので難しそうですが…)
↓手動だった頃の記録
『ゆゆ式』9巻 店舗別特典まとめ - 茶番のアレ https://t.co/AhErdvqXue 描き下ろし以外もまとめてくれてる方がいました!
— 三上小又@ゆゆ式12巻発売!! きららファンタジアやってるよ。 (@mikamikomata) 2017年8月23日
(更新中)ゆゆ式11巻 店舗別特典まとめ
ゆゆ式11巻特典まとめ
8/27追記
きらら公式から特典告知がありましたので貼っておきます。
ゆるっと最新刊。三上小又先生の「ゆゆ式」11巻は本日発売です!
— まんがタイムきらら編集部 (@mangatimekirara) 2020年8月27日
各書店様の購入特典情報をまとめてみました。
お買い物にお役立て頂けましたら幸いです。 pic.twitter.com/WfgiKE9Gja
以下は一応残しておきますがほぼ不要かと思います。(アニメイト秋葉原店の専用特典とかは載ってます)
ゆゆ式tenに当たらなかったので更新頻度低めです。多分あってるとは思いますが、まとめた内容があっているかは保障できないので、きらら公式ツイッターによる告知が出たらそちらをご確認していただいたほうが安全かと思います。
※通販サイトで売り切れでも店舗にある場合があります。
※メロンブックスのタペストリーと、ゲーマーズのアクリルスタンドは限定セットのみついてきますのでご注意ください。
以下特典一覧です。
オリジナルブロマイド

オリジナルブックカバー

ゲーマーズ限定セット アクリルスタンド

特製ブックカバー

特製クリアファイル


しおり

別途
8/27(木)から秋葉原店限定で『祝!ゆゆ式 第11巻発売記念フェア』として、ゆゆ式の単行本または『まんがタイムきらら』1冊購入ごとに1枚特典ブロマイドの配布があるそうです。(特典はなくなり次第終了となります。)
なお、全9枚のうち7枚目までは10巻の同様のフェアのときと同じもののようです。
【書籍フェア情報】8/27(木)から『祝!ゆゆ式 第11巻発売記念フェア』が開催決定です✨期間中、対象商品1冊につきお好きなブロマイド(全9種)を1枚プレゼント‼秋葉原本館限定フェアとなりますのでお見逃しなく‼ #yuyushiki #kirara #ゆゆ式 pic.twitter.com/BlcX4irySo
— アニメイト秋葉原本館 (@animateakiba) 2020年8月22日
・COMIC ZIN
4P冊子

・その他共通書店
描き下ろしペーパーのようです。書店は不明ですが喜久屋書店はあるようです。

【特典情報】芳文社 #三上小又 先生『#ゆゆ式 11巻』(8/27発売予定)には特典ペーパーが付きますーヾ(○・ω・)ノ先生ありがとうございました(*´∀人) pic.twitter.com/7dsokfateq
— 喜久屋書店仙台店(キクちゃん) (@kikuchan2013bot) 2020年8月26日
ソース以下
11巻発売まであと4日!!!近い!!!! 今回は完全に余裕がなくて描き下ろし特典はペーパーだけです 連載4pに減らしても余裕は作れませんでした…
— 三上小又@ゆゆ式11巻8/27 きららファンタジアやってるよ。 (@mikamikomata) 2020年8月23日
今回描き下ろしの特典はないそうですが、ペーパーは描き下ろしのものがあるそうです どこの店舗?って聞いたらわかんないと返答が
— 弘崎真史 (@s_hirosaki) 2020年8月20日
追記
共通ペーパー店舗や、きらら公式の告知があったりした場合また更新するかと思います。
8/26追記 共通ペーパー画像追加
8/27追記 きらら公式の告知貼り付け
まちカドまぞく原作を特定のワードで検索して画像を表示できるようにしてみたかった。(未完成)
・まちカドまぞく原作を特定のワードやキャラの出番ごとに検索できるものを作りたかった。
結論を言うとまだ完成してはいないんですが、時間をかければそこそこなんとかなりそうな感じです。ちなみに作成できてもマンガの全部のコマが読めてはたいそう問題があると思うので公開はできません。
まちカドまぞくについて、キャラごとの台詞をまとめたいとか、こんなワードが出てたようなとか思ってもページをめくって探すのが大変… などと思うことはないでしょうか。そう思ったので、以下のようなものができないかと考えました。
・特定のワードで検索ができる。
・キャラごとの出番を絞り込める。
・検索や絞り込みをすると、そのコマが表示される。その際に巻数、ページ数も表示される。
以上の3点の作成を目指して色々やってみました。
環境:windows10(macでも動くようです。)エクセルは必要です。
・だいたいS治さんの同人誌、『4コマ漫画のデータ収集と分析による評論の可能性(with Python)』を参考にしました。
COMIC ZIN 通信販売/商品詳細 ポストモダンのポリアネスtech. 〜4コマ漫画のデータ収集と分析による評論の可能性〜
内容としては、Pythonで4コマ漫画のjpgデータををコマごとに切り分け、それをOCRで画像の文字を読み取って分析するというものでした。この動作をするファイルはGitHubに公開されているのですが、GitHubが何かよくわからずPythonも知らない身としてはなかなか意味がわからなかったですが、どうにか動作はできました。
https://github.com/esuji5/yonkoma2data
やり方は上記のページに記載があるので下のは備忘録程度の作成メモです。
ちなみに中盤でエラーを解決できず一月ほど放置したため前半の記憶が曖昧なので、何か間違ってるかも知れません。
なお、PDFファイルのバーコード(JANコード)を読み取り自動リネーム
PDFファイルをページ毎のPNGファイルに切り出す
の2点については使用しませんでした。
①Pythonを入れる。
https://www.python.jp/install/windows/install_py3.html
②OpenCVを入れる
参考:https://qiita.com/ideagear/items/3f0807b7bde05aa18240
③gitの導入とgithubに登録
参考?:https://employment.en-japan.com/engineerhub/entry/2017/01/31/110000
⑤コマンドプロンプトcd でyonkoma2dataファイルのあるフォルダに行き、
py -m pip install -r requirement.txt を入力
このとき何か読み込まれたあとエラー出ましたけど問題はなかったです。
⑥jpgのデータを用意する。(私は秋葉で裁断用のまぞくを1~5巻購入し、裁断とスキャンできる店でjpgデータにしました。)
⑦傾き補正、美白化を行う。
ImageMagickのインストール
参考:https://higuma.github.io/2016/08/31/imagemagick-1/
cd path/to/jpgs→コマンドプロンプトでcd (画像のあるフォルダの場所) という入力ですね。その後
mogrify -level 25%,83% -deskew 40% -density 200 *.jpg
を入力すればいい感じになるようです。数値の微調整はよくわからんです。
⑧ページ毎のJPGファイルを1コマ毎のJPGファイルに切り出す。
python amane_cut.py path/to/image_dir (path/to/image_dirは画像のあるフォルダの場所です。)を実行できればよいはずですがなぜかできませんでした。
エラー python: can't open file 'amane_cut.py': [Errno 2] No such file or directory
調べたところパスを通すとかなんとかあるので通してみました。
参考:http://realize.jounin.jp/path.html
しかしそれでも動かないので、Pythonファイルをvscodeというエディターで開いてみました。(VScodeの導入はS治さん共著の『スラスラわかるPython』を読みました。)
開いてみましたが同じエラーが出ており、「開いてるのに無いって何いってんだ…」状態なので、ドキュメント下にフォルダごと動かしてみたところ読み取りはできましたがエラーがたっぷり出ました。
エラー内容はインポートができていない様子なので、該当のファイルのパスを通したらなんとかなりました。
そして、実行したところ無事に動作。概ねコマごとに切り分けできました。
⑨コマ中のセリフを抽出する
(注)OCRはいっぱいやると有料っぽいです。
(1)prepare Google Cloud Platformのアカウント作成
(2)コマンドプロンプトでpip install google-cloud-vision でインストール
(3)Cloud Vision APIを有効化し、API keyをjsonで保存する
参考:https://www.asobou.co.jp/blog/web/vision-api
(4)jpg_to_ocr.pyの調整
43行目辺りに
key_file_path ='/Users/esuji/Dropbox/program/cvtest/yonkoma2data/src/MyFirstProject-b8427fd28b8d.json'
とあると思うのですが、' 'の間を(3)で取得したjsonのパスに変更したら動きました。
また、53行目辺りの
for idx_koma, image_path in enumerate(image_path_list[100:110]):については[ ]内が何枚目から何枚目と指定しているようなので、1枚目から100枚目まで取得したければ[0:99]などと調整がいるようです。
(5)画像をOCRをにかける
python jpg_to_ocr.py path/to/image_dir_path/ OCR結果は path/to/pickle/image_dir_path(_master).pickle に保存されました。
python3 pickle_to_serif_data.py ~/image/rename_test/pdf_to_jpg/ato.pdf/2_paint_out/0_koma/pickles/0_padding_shave_master.pickle
これでCSVファイルができました。
ただ、初回では読み取りが横書きのように読まれてるようで妙におかしかったので、125行目あたりのif sum(is_yokogaki_list) >= len(self.ta_list) / 2:後から
return ''.join(text_list)
else の前までをコメントアウトしたらよい感じになりました。
何かもっとエラーがあった気がするのですが、そこは適宜検索してください(私はここまでで12時間くらいかかりました。)
ここまでがGItHubで記載のある内容です。
CSVをエクセルで整える
ここからは個人的に作成したものになります。
先ほど作成できたCSVはこんな感じで、画像のパスと出力されたセリフになります。

この状態では画像のパスとセリフだけなので、キャラも誰が出てるかわかりませんし、ページ数も不明です。そこで、色々調整していきます。
(1)コマ画像を貼り付け
パスの右のセルに画像を貼っていきたいと思います。
作業はVBAでやっていくので、上のタブに開発タブがなければオプションのリボンのユーザー設定から開発にチェックを入れてください。
開発タブを開いたら左端のvisualBasicを開きます。
その後標準モジュールを作成します。

では、マクロで作業を進めていきます。
まず、CSVが1行ごとに空行になっているので消します。
手作業だと面倒なのでマクロにしておきます。
Sub 行削除()
Dim i As Integer
For i = 4 To 1654
Rows(i).Delete
Next i
End Sub
こんな感じで削除しました。4To 1654は指定の行数ですが、必要であれば調整してください。この記述方法は問題がある気はしますが一応動きました。
次はB列を画像の列にしたいので、手動でB列の横幅を調整。縦幅も適宜調整しました。
見やすい程度に調整してください
次はマクロで画像を貼ります。
標準モジュールを再度作成し、
Sub 画像貼り付け()
Dim p As String
Dim i As Integer
Dim j As Integer
For i = 3 To 829
p = Cells(i, 1)
With ActiveSheet.Pictures.Insert(p)
.Top = Range("B" & i).Top
.Left = Range("B" & i).Left
.Width = Range(Cells(i, 2), Cells(i, 2)).Width
.Height = Range(Cells(i, 2), Cells(i, 2)).Height
End With
Next i
End Sub
これで実行すれば3行目から829行目まで画像が貼られていきます。
次はページ数とコマ数です。オートフィルでいけるのではと思いましたが、CSVになるまでに消滅するコマなども存在するようでだめでした。
今回はページ数とコマ数が画像ファイル名から読み取れそうなのでそこから出しました。
Sub ページ数記入()
Dim i As Integer
Dim p As String
For i = 3 To 829
p = Cells(i, 1)
Cells(i, 3) = Mid(p, 61, 3) - 2
Next i
MId(利用する文字列,何文字目から,何文字)という形なので数値は調整してください。-2はページ数とファイル名が合ってなかったのでその調整です。
コマも同様に
Sub コマ数記入()
Dim i As Integer
Dim p As String
For i = 3 To 829
p = Cells(i, 1)
Cells(i, 4) = Mid(p, 65, 1)
Next i
End Sub
これで画像、ページ、コマ、セリフまでは一応出たところです。
最後に登場人物になりますが、手入力になります。入力用のツールもあるようですが、使い方がわかりませんでした。
GitHub - esuji5/data_annotator: data annotator from Web app
というわけでエクセルでできる範囲で作業を簡略化してみました。
セルをクリックしたら◯がつくような便利なものはないかと調べたところありましたので使います。
参考: https://www.forguncy.com/blog/20181217_clickevent
上記を参考に入力
Private Sub Worksheet_SelectionChange(ByVal Target As Range)
If Target.Count > 1 Then End
If Not (Target.Row >= 3 And Target.Row <= 830 And Target.Column >= 7 And Target.Column <= 20) Then End
If Target.Value = "〇" Then
Target.Value = ""
Else
Target.Value = "〇"
End If
Application.EnableEvents = False
Range("A1").Select
Application.EnableEvents = True
End Sub
これでセルをクリックすると◯が入るようになりました。
あとは○が入っていればキャラ名が出るようにif文を配置し、こんな感じになりました。(画像は後から粗くしてます)

あとはコマを見てセリフの誤りを修正し、セルをクリックして登場人物に○をつけていけば完成です。これだとフィルターがかからないのでまとめ用のシートに値を貼り付け等で写す必要はありそうですが…
問題点
量が多い。1巻あたり800コマ以上あるので、○をつけるのも、そこそこ違ってるセリフを修正するのも大変。○をつけるだけなら数時間あればできそうですが、セリフの修正も込みだと1時間で120コマ程度→5巻分やると40時間程度… これはやる気がしない。
また、コマが一部飛んでいたりして手作業での修正が必要なところもありました。
サブタイトルが消失している…→サブタイトル付き切り抜き手法もある様子
まとめ
入力に時間がかかりそうですが、出来上がりさえすれば検索したりキャラごとの出番を抽出をすることも可能そうでした。しかし、ひたすら時間がかかりそうなため、時間削減のために精度を上げたりキャラを抽出したりしたいですが、Pythonの文法も知らない自分の技術力でやるのは現実的に厳しいので、そのあたりは新しいものが出るのを待つ感じでしょうか…
また、きららフォワードなど4コマでないものはOCRで読み取ると文字の順序がめちゃくちゃになったりしてまともに読み込めなかったので、ストーリー誌もコマごとに分割できて4コマ以外もできるようになったら良いなあと思いました。
まちカドまぞく9話 世界史Bの回答について
あけましておめでとうございます。茶番の民です。
今年はまちカドまぞくの2期があるようにどうにかできる範囲のことをしたいところです。

さて、誠に茶番でございますが、年賀状の素材を探す中で見つけたこの画像。

何が書かれているのか検討する。ただそれだけでありますが…
画面上で確認できるのは1-(1)~(6)、3-(1)~(3)と(5)(6)(9)でしょうか。
では見てみましょう。
1
(1)オリエント
(2)ユーフラテス
(3)メソポタミア文明
(4)楔形文字
(5)ジッグラト
(6)太陽暦
3
(1)パルティア王国…? ヒッタイトの前にこれが来るのはおかしい気も
王国までは読めるが…
(2)ハンムラビ法典
(3)ヒッタイト
(5)ファラオか…? ア、が強引に思えるが…
(6)解読できませんでした。 3文字程度で最後がフかアに見えますが…ペルシア…?
強いて言えば前がファラオだとするとパピルス…?
(9)アッシリア
高校の世界史の資料集を見ながら解読してみましたが、きっちり載っている範囲でしたね。解読がやけに難しい気がしましたし、あってるのか自信のないものもいくつかありましたが…あと、資料集読んでてヒッタイトを倒した海の民つよいと思いました。
まちカドまぞくのイベントに行った
・まちカドまぞくのイベントに行った
うらら迷路帖のイベント以来、2年4ヶ月ぶりのアニメイベントに参戦。
円盤売上が好調なこともあり、物販も盛況で、物販開始時刻ぐらいに着いたのにめっきり売り切れでした。一般購入勢は何も買えなかったという話も…
まあ、売れてるのは良いことですが…
なお、事後通販があるそうですが、受注販売のようなので忘れずにお買い求めください。設定資料集は評判が良いらしいので欲しいところ。
・二期の告知はなかったが…
妙に勢いを感じるので、もしかしたら二期の告知があるのではと思い参戦するも、告知はなかった。売上的には2期のあるきららの最低ラインは下回りつつもOVAのあるGAラインは超えてる微妙な情勢。
とはいえ、近年は動画サイトの収入があるとか、物販が売上好調とか原作が売れすぎてやばいとか色々聞くのでまだまだ可能性は十分ありそうですね。
とりあえず、3巻以後も円盤を買って様子見というところでしょうか。

これすき