風来のシレン2の被ダメージ計算式について
シレン2で被ダメージを計算する際に、ダメージ計算式の切り捨て等の小数点以下の扱いに不明なところがあった。(平均ダメージ、最大・最小ダメージの部分)
Wikiにも詳細の記載がなく、調べても詳細の記載は見つからなかったため、エミュレーターでアセンブラを読んで確認を行った。
なお、今回は通常攻撃時の被ダメージのみ調査しており、印の影響や攻撃時のダメージは未調査である。
Wikiの記載について
ダメージ計算式についてはWikiに下記のように記載がある。
https://shiren2.lsx3.com/?%B4%F0%CB%DC%A5%B7%A5%B9%A5%C6%A5%E0#atk
モンスターの攻撃力はちから+1
盾を装備していないシレンの守備力は0
シレンとアスカが盾を装備していた場合、盾の強さ/2(小数点以下切捨て)が守備力として加算される。
平均ダメージ=攻撃力*((35/36)^守備力)
最大ダメージ=平均ダメージ+(平均ダメージ/8)
最小ダメージ=平均ダメージ-(平均ダメージ/8)
結果:
最大ダメージ、最小ダメージは切り捨て。
Wikiの攻撃力の記載等に合わせると以下の通り。
最大ダメージ=int(平均ダメージ+(平均ダメージ/8))
最小ダメージ=int(平均ダメージ-(平均ダメージ/8))
平均ダメージは切り捨てる箇所と切り捨てない箇所があるため下記の詳細に記載。
詳細:
平均ダメージを求める際のダメージ減衰は「(35/36)^守備力」を直接計算しているのではなく、守備力に合わせて下記の(35/36)^(1,2,4,8,16,32,64,128) の係数テーブルを順に掛けている。*1
係数をかけた際は切り捨てるが、最後の1回は切り捨てずにそのまま平均ダメージとする。
例:
守備力7のとき
攻撃*F8E4((35/36)^1)→切り捨て→攻撃*F1FA((35/36)^2)→切り捨て
→攻撃*E4B8((35/36)^4) (ここは切り捨てない)
守備力8のとき
攻撃*CC58((35/36)^8)(ここは切り捨てない)
係数テーブル(16進):
(35/36)^1 → 0xF8E4
(35/36)^2 → 0xF1FA
(35/36)^4 → 0xE4B8
(35/36)^8 → 0xCC58
(35/36)^16 → 0xA31D
(35/36)^32 → 0x67EE
(35/36)^64 → 0x2A31
(35/36)^128→ 0x06F4
(35/36)^256→ 0x0030
その後、求めた平均ダメージに対して7/8~9/8の範囲で乱数を掛け、切り捨てた値が被ダメージになる。*2
よって、最大・最小ダメージは以下の通り
最大ダメージ=int(平均ダメージ+(平均ダメージ/8))
最小ダメージ=int(平均ダメージ-(平均ダメージ/8))
なお、結果が0ダメージの場合は1ダメージになる。
各ダメージの確率について
最終的なダメージは切り捨てであるが、切り捨て前のダメージの範囲によって最大・最小になる確率は下がる。最大・最小以外は一定。
例:守備力3(ばん族の盾)で女王グモ(攻撃力30)の攻撃を受けた場合。
最大ダメージ:約30.84
最低ダメージ:約23.98
このような場合のダメージごとの確率の概算は以下のようになった。
| ダメージ | 確率 |
| 23 | 0.2% |
| 24 | 14.6% |
| 25 | 14.6% |
| 26 | 14.6% |
| 27 | 14.6% |
| 28 | 14.6% |
| 29 | 14.6% |
| 30 | 12.2% |
ダメージの切り捨て処理による修正値上昇時の弱体化について
守備力によるダメージ減衰では切り捨てが入るため、切り捨て時の小数次第で低攻撃力帯では「守備7より守備8の方が被ダメが増える」等の逆転が起きる場合がある。(高攻撃力帯になるにつれて、守備8の方が被ダメが少なくなる)
具体的には守備力が7→8、15→16、31→32になる瞬間などでは、切り捨て回数の影響で守備力が上がる前より弱くなることがある。
逆転する具体例:
・守備力7で攻撃22の攻撃を受けたとき。(象牙の盾+3で水龍の攻撃を受けた場合)
平均ダメージ:約16.9
ダメージ範囲:14~19
・守備力8で攻撃22の攻撃を受けたとき。(象牙の盾+4で水龍の攻撃を受けた場合)
平均ダメージ:約17.6
ダメージ範囲:15~19
逆転しない具体例:
・守備力7で攻撃32の攻撃を受けたとき。(象牙の盾+3でパオパ王の攻撃を受けた場合)
平均ダメージ:約25.9
ダメージ範囲:22~29
・守備力8で攻撃32の攻撃を受けたとき。(象牙の盾+4でパオパ王の攻撃を受けた場合)
平均ダメージ:約25.5
ダメージ範囲:22~28
2026/2/23追記
上記の結果を踏まえた簡単な計算機を作成しました。
注:
1:実際の処理では固定小数点を使っており、最初に65536を掛けている。
2:実際の処理では(平均ダメージ/8)の値を求めてから、「0~(平均ダメージ/8)」の範囲の値を乱数で生成。その後に、乱数でプラスかマイナスかを判定し、平均ダメージに加算または減算して切り捨てている。
Yomitoku、yonkoma2dataを用いたきららコミックスのOCRについて
以下の記事は、「Yomitoku 、yonkoma2dataを使ったきららコミックス(まちカドまぞく5巻)の OCR作業の備忘」です。年末年始の連休内で実行しようとやっつけ作業の部分が多々ありますが、同様の取り組みを検討している方の参考になれば幸いです。OCR結果を最終的にエクセルファイルに文字情報とコマ画像をまとめるまでの一連の流れを紹介します。
0. 前提
- 年末年始の連休で、「とりあえず動かしてみる」程度で行った作業です。成果は限定的で、やっつけ感があることをご了承ください。
- なお、今回は下記の記事の続編にあたります。
まちカドまぞく原作を特定のワードで検索して画像を表示できるようにしてみたかった。(未完成) - 茶番のアレ
1. 導入や背景
Yomitoku を使用する経緯
- 以前はこちらの本を参考にGCP Vision APIでOCRを行っていましたが、GCP Vision APIだと一定枚数以上で有料になるため、気軽に大量ページを処理したい場合には使いづらいと感じました。
- 無料OCRではGoogle Document の OCR 機能を使う先行事例(じょいゆさんの記事)もありましたが、今回は 日本語に特化した AI OCR「Yomitoku」 が気になり、試してみることにしました。
4コマ漫画を対象としたテキスト抽出作業の自動化とデータベース作成 - 涅槃茄子
- 4コマ漫画をテキスト化すると、「このセリフ、どこだっけ?」 という検索が一気に楽になるメリットがあります。
環境
- OS: Windows 10
- Python: 3.12
- Yomitoku: v0.6.0
- GPU: GTX1660(VRAM 6GB)
- Yomitoku は 公式ドキュメントによるとVRAM 8GB以上推奨らしいですが、一応動作しました。
- CUDA: 12.1
- Excel 2016
GPU は推奨スペックに届いていませんが、GPUを使用すると1 コマあたり 約5秒 → 約1秒と短縮でき、なかなかの時短になりました。単行本1冊分でおよそ 1000 コマがあり、GPU を使用した場合12 分程度で完了しました。
2. 実装手順や利用ツール
全体のフロー
まずはコマ画像を準備する必要がありますが、今回は数年前の前回の記事の際に用意していた画像データ(まちカドまぞく5巻)を流用しました。
その上で、以下のステップで処理を進めています:
- コマ切り抜き (amane_cut.py)
- 画像拡大 (kakudai.py)
- OCR (Yomitoku) → CSV 出力 (ocr_kakou.py)
- マクロ付き Excel に画像挿入 (csv-excel.py)
各ステップごとに、以下のプログラムを利用しました。
2-1. amane_cut.py
- ページ全体の画像から 4コマ漫画をコマ単位で自動切り抜きしてくれます。
- S治さんの著書『ポストモダンのポリアネス tech. ~ 4コマ漫画のデータ収集と分析による評論の可能性(with Python) ~』で解説されている
yonkoma2dataに同梱のプログラムです。下記のgithubからクローンして使用しました。 - 参考:
ポストモダンのポリアネス tech. ~ 4コマ漫画のデータ収集と分析による評論の可能性(with Python) ~ - esuji - BOOTH
2-2. kakudai.py
- 短辺を 2000px 以上にリサイズするプログラム(INTER_CUBIC で拡大)。
- Yomitoku が短辺 1000px 以上を推奨しているので、より余裕をもたせています。
- 当初の700×500px程度の画像と比べ、 OCR 精度が上がった印象がありました。
2-3. ocr_kakou.py
- Yomitoku で OCR → JSON 出力 → CSV 変換 する流れをまとめたもの。
- Yomitoku は多彩な出力形式(json/csv/html/md 等)がありましたが、縦書きが含まれるため JSON が最も安定して取り込めました。
- OCR結果の JSON の中身を取り出し、「ファイル名(画像パス), コマ画像, セリフ」の形で コマ画像1枚ごとに1行としてCSV を作成しています。
2-4. csv-excel.py
3. 調査対象
- 伊藤いづも先生『まちカドまぞく』5巻
・選定理由
文字数についての参考記事:
きららのコミックス第1巻の文字数をOCRで数えて比較してみました(OCRなので人間が数えるより正確ではないです)。一番文字量が多かったのはステラのまほうでした。 pic.twitter.com/hpe2LjJU9P
— たろとみ (@tomi_taro) 2022年9月30日
- 下記はWindows10 上での手順を備忘録としてまとめています。Mac/Linux は未検証(CSV → Excel + マクロ挿入については、win32というwindows用のプログラムを使用しているのでMac/Linuxでは動かないと思われます。)
実際の手順まとめ
- Python 3.12 をインストール
- amane_cut.py などが 3.12 を想定しているため、公式サイトから最新版を導入。
- Yomitoku のインストール
- 公式ドキュメント等:
-
- 最初は
pip install yomitoku[gpu]を試みるも、windowsではlibraqmがpipでインストールできず縦書きの文字について警告が出た。 - 結果的に
uv sync --extra gpu(パッケージ管理ツール uv)で入れ直し、CUDA 12.1 に合わせた PyTorch を再インストールし動作確認。
- 最初は
- yonkoma2data のクローン
- https://github.com/esuji5/yonkoma2data から
amane_cut.py等を入手。 - requirements のバージョンが Yomitoku とやや不整合だったのでYomitokuに合わせて、新しいバージョンに微調整。
- https://github.com/esuji5/yonkoma2data から
- コマ切り抜き
amane_cut.py path/to/pages --ext png -y 5 -x 20- 今回の所持していた画像が PNG なので
--ext pngを付与。ページ座標に合わせて -y, -x を調整し、コマ画像を切り出す。
- 画像拡大 (kakudai.py)
- アスペクト比を保ったまま短辺 2000px 超に拡大。
- OCR と CSV 出力 (ocr_kakou.py)
- CSV → Excel + マクロ挿入 (csv-excel.py)
結果:
出力結果のエクセル抜粋:
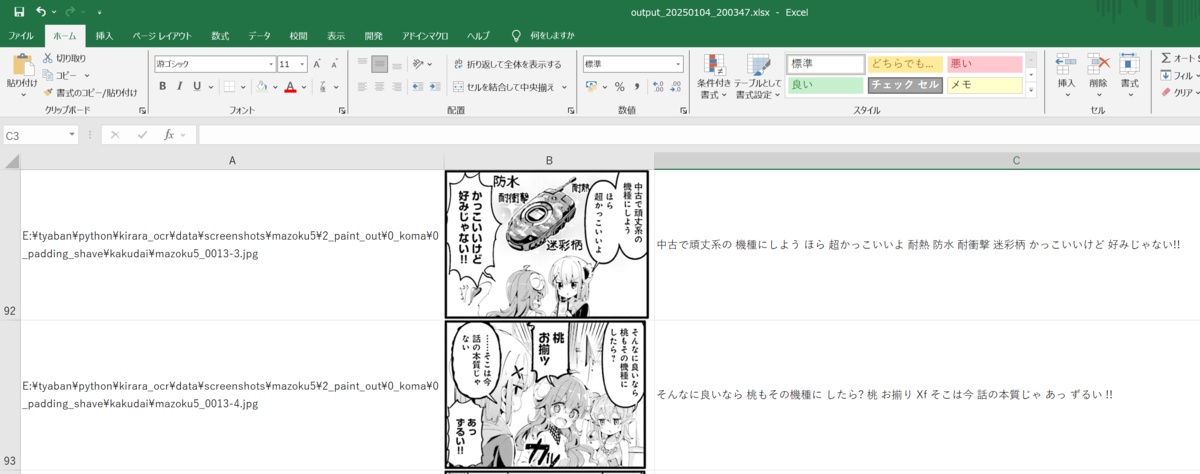
4. 実際にやってみてわかった課題
-
縦2行のセリフが1行と認識される場合がある
- 行間が狭いコマで文字がくっついてしまい、意図しない読み取りに。
- 対策案:
- さらに高解像度画像を使う(裁断スキャン時に高dpi取得等)
- 画像のコントラスト調整を行ってみたがあまり効果はなかった。

-
背景の絵柄や吹き出し外の文字をゴミとして拾う
- たとえば数字や「っ」など。
- S治さんの yonkoma2data にはゴミ取りスクリプト (pickle_to_serif_data.py) があるので、同様の仕組みを導入すると良さそう。
-
語順が崩れる
-
そもそもの解像度が足りない可能性
- 使用した画像が200dpiだったため、一部の文字がぼやける箇所もあった。600dpi などの高解像度でのスキャンが良いかもしれません。
5. 今後の展望・補足情報
- Meilisearch などで全文検索をローカル実装すると便利。
- ただ、今回は時間がなかったため Excel 上の検索で妥協しました。
- 下記を参照してローカルで実装したことがありますが、見た目や使い勝手は良かったです。ただし、設定にもうひと手間かかるので、それも含めて自動化できるようにしたいところです。
参考:ポストモダンのポリアネス tech. セリフ検索システムの構築編 - esuji - BOOTH
- 登場キャラクターの自動判定
- 画像の事前処理はあまり試せていなかったので、もっと丁寧にやれば精度はさらに上げられると思われます。
6. 備考
自作部分は下記に格納しております。
GitHub - tyabannotami/ocr_kirara_pubric: きららコミックスのOCR
まとめ
- Yomitokuを使用してのきららコミックスの OCR は、無料かつ日本語特化のメリットを活かし、大量のコマを手軽にテキスト化する可能性を感じました。
- GPU で処理すると 1 枚あたり 1 秒弱と高速。CPU なら 5 秒弱かかり、単行本 1 冊分の作業時間が大きく変わります。
- 縦2行のセリフが1行と認識される問題や背景との誤認識など、まだ十分でないところもあります。今後は高解像度スキャンや追加の画像処理を試して精度向上を図りたいところです。
なお、上記の文章は実際の作業結果のメモを元にChatGPT o1 proで生成した文章を加筆修正しています。自作部分のPythonプログラムは概ねChatGPT o1 proで生成したものを微調整したものです。
『またぞろ。』の掲載順位調査(最終)
『またぞろ。』の掲載順位についての調査の見直し。
・目的
またぞらーの茶番の民です。
『またぞろ。』がアニメ化するのか3乙するのか4乙するのか気になるので以前別の記事で調べてみましたが、結果的に3巻で完結しました。
なお、統計は相変わらずよくわかりませんが、掲載順が最終まで見えたので再度記事にしました。
・調査方法
前回記事と同一のプログラムで集計後、エクセルで整形しました。
・調査結果
非アニメ化3巻以上完結について
きららキャラットでアニメ化にはならず3巻以降で完結した作品の最終12話と現在の『またぞろ。』の掲載順を抽出したところ下記の表となりました。

結果的に、『またぞろ。』の平均順位数は前回より上がり8.3となり、他の作品より4.9ほど高い結果になりました。
また、センターカラー数も前回から増加し5となり、平均の倍となっています。
他の要因を調査
順位は良いのになぜ3巻で終わったか理由がないかを見ていたところ、以下の2つが思いつきました。
・掲載再作品数
きららキャラットはここ5年ほどで25作載っていたのが20作ほどに減っています。(図ー最終回の掲載作品数列参照)
そのため、掲載作品数に対してどれくらいの割合の位置に掲載しているかも調査してみました。(図ー掲載順位の割合列参照)
結果的に『すわっぷすわっぷ』に近い数値でしたがそれでも最も良い数値ではありました。
・アニメ化作品数
数年前はきららキャラットはアニメ化作品だらけだった気がしたので、その時期に連載が継続していたアニメ化作品数も調べてみました。図ーアニメ化作品の掲載数列参照)
ここでは、アニメ化作品数が2016年代は8、2019年代は10と現在の5に比べて多くなっていました。他作品はアニメ化作品が上位に来て、掲載順位が下がっていた可能性はありそうです。
・結論
以下のことが言えそうな気がしました。
・昔より掲載作品数が減っているので、掲載順位が良さそうでも案外3巻で終わったりする。
・アニメ化作品数で掲載順位が左右されがちのため、アニメ化作品数が少ないときは掲載順位が高めでも完結しやすい。
→現在のキャラットにおいては、『またぞろ。』ほどの掲載順位、カラー数でも3巻で終わる可能性が高そう。
・感想
掲載作品数が減っているというのを調査を通じて気が付きましたが、その分連載継続も厳しくなりそうでなかなかつらいところがあります。
幌田先生の次回作を期待しております。
まんがタイムきららキャラットの掲載順位に基づいた『またぞろ。』のアニメ化実現可能性および3巻乙の可能性の調査について
『またぞろ。』はアニメ化するのかどうか
・目的
またぞらーの茶番の民です。
『またぞろ。』がアニメ化するのか3乙するのか4乙するのか気になるので調べてみました。
なお、統計はよくわからず、結果的にアニメ化するかはよくわかりませんでしたに帰結しました。3乙はなさそうな傾向が見えました。
・先行研究について
きらら系列の掲載順位についての先行研究では下記サイト「四コマの調べ屋」がありました。このサイトでは掲載順位に基づき、2巻乙か3巻以上になるかを調査しているようです。
しかし、アニメ化についてや3巻以降の完結については調査が見つからなかったので今回は独自に調査を進めるところです。
また、きららサーチでは作品名や著者名などで検索が可能であり、作品の順位をすぐ調べたいときなどはとても役立ちます。
・調査方法
今回はきららキャラットの掲載順やカラー回数などをエクセルで一覧化し調査をおこなました。
まず、掲載順とカラー回数の抽出には先行研究がありましたので、下記のサイトを参考にしました。
上記サイトのソースからセンターカラーでの掲載号の記載、抽出対象作品の変更、CSV出力への変更などを行い抽出しました。
ソースとcsvは下記に格納しております。
その後抽出したデータをエクセルで整形し調査を行いました。
なお、掲載順の調査範囲としては昔過ぎても情勢が変わっていると考えたため、2013年1月号以降を対象としています。
・調査結果
アニメ化について
2013年以後のきららキャラットのアニメ化作品のアニメ化決定直近12話と、現在の『またぞろ。』の掲載順を抽出したところ下記の表となりました。
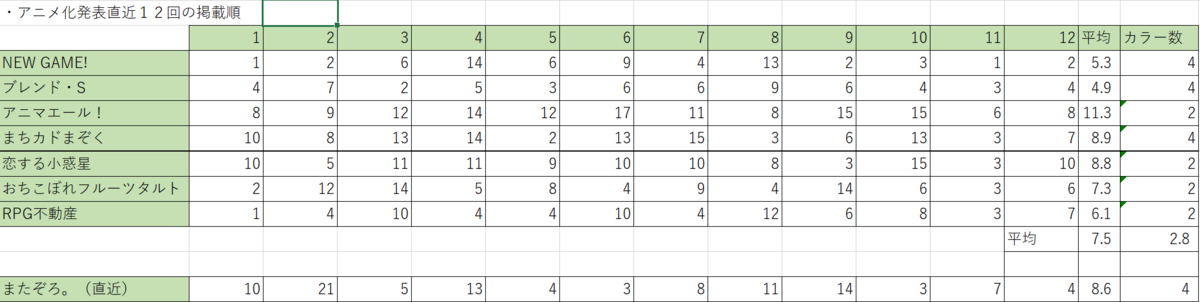
これを見ると、『またぞろ。』の掲載順はアニメ化作品の平均よりやや低いですがカラー数は多いことが見受けられます。また、『まちカドまぞく』や『恋する小惑星』の数値とほぼ同等であるためアニメ化の可能性は十分ありそうです。
3巻乙について
きららキャラットでアニメ化にはならず3巻以降で完結した作品の最終12話と現在の『またぞろ。』の掲載順を抽出したところ下記の表となりました。
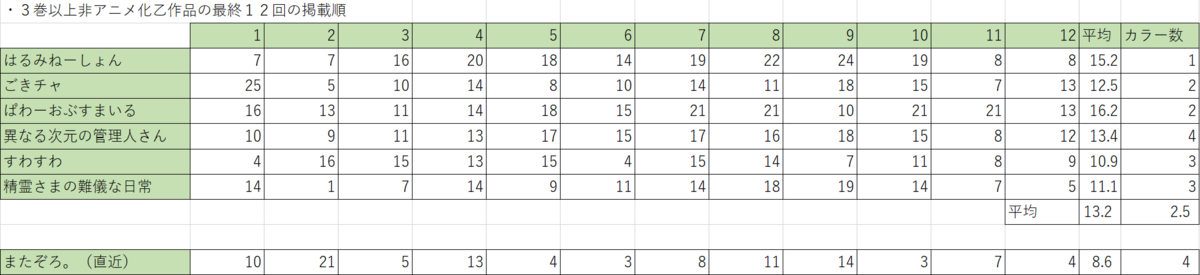
この表では、平均の掲載順が『またぞろ。』のほうが4.6ほど高くなっており、カラー数も多くなっています。最も掲載順が良かった『すわっぷ⇔すわっぷ』でも10.9でありまたぞろより。2.3低いため、この数値から考えると『またぞろ。』の3巻での完結はあまりなさそうと思われます。
3巻以降で完結した作品の最大値について
きららキャラットでアニメ化にはならず3巻以降で完結した作品の12話での平均掲載順位の最高区間と現在の『またぞろ。』の掲載順を抽出したところ下記の表となりました。
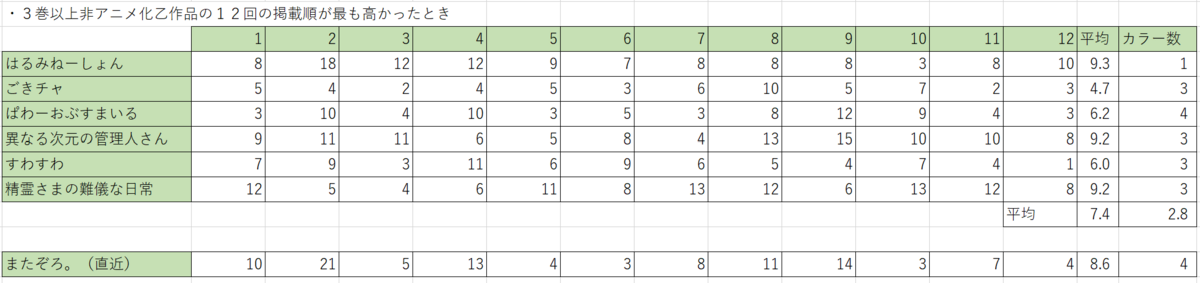
なお、アニメ化作品のアニメ化決定直近12話はこちらです。
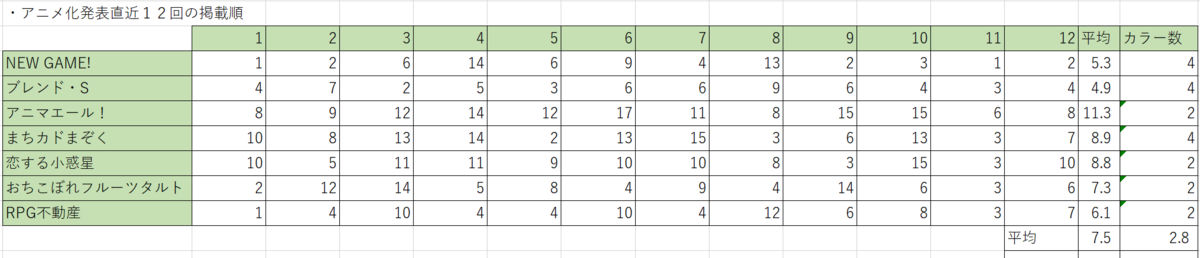
上記の表からすると、3巻以上でアニメ化せずに完結した作品はアニメ化直近12回とほぼ同等の掲載順位を経験していることがわかります。『ごきチャ』に至ってはアニメ化直近12話で最大の『ブレンド・S』より高い掲載順位でした。
・結論
以下のことが言えそうです。
・『またぞろ。』はアニメ化した作品との掲載順にそう差がないのでアニメ化する可能性は十分ある。
・『またぞろ。』非アニメ化の3巻以降の終了作の最終12話より掲載順が高いので3巻での完結はなさそうな気がする。
・アニメ化しなかった3巻以降終了作でもアニメ化直近12話と同等の掲載順位は経験するが、そのうち掲載順が落ちて完結になる。
→『またぞろ。』は現在の順位が続くうちはアニメ化の期待ができるが、順位が落ちてくると終わりが来そう。
・当調査の課題
・2013年~2019年頃のキャラットは25作掲載していたが直近は20作。単純に順位数だけで計算してよかったか
・アニメ化作品数の違い
2018年6月号はアニメ化作品が10作載っていた。直近の2023年3月号は4作とアニメ化作品の掲載数が倍以上違う
・余談
『またぞろ。』以外でも、キャラットで掲載中の2巻突破作品は3つほどありますがそれらとの比較がこちら。

どれも『またぞろ。』より掲載順位が良いので、アニメ化もあるのでしょうか。
ゆゆ式の特典確認の自動化について
この記事はゆゆ式Advent Calender 10日目の記事です。https://t.co/1JD2xTax2Y
#ゆゆ式ac
○ゆゆ式の特典確認の自動化について
・目的
ゆゆ式の単行本特典をpythonで自動確認しようというものです。(今となってはほぼ不要なものですが…)
なお、筆者は仕事でPythonを扱ったりしているわけではなくほぼ素人のコードになりますのでコードがアレなのはご了承ください。(一応動きました。)
・経緯
ゆゆ式の単行本はいまでこそきらら公式ツイッターで特典が公開されていますが、数年前までは公式告知がなく、作者の方が告知するなり読者が自分で各店舗のサイトを見て調べるなどしていた時代がありました。
過去に自分で調べてこんな画像を作ったりもしてました。

そこで、当時は自力で手動で確認していたわけですが、毎日各店舗のサイトを確認するのもなかなか面倒という問題がありました。というわけでプログラムで定期実行して楽をしたいという思いがありました。今となっては不要ですが、作れそうなので作ってみたところです。
・自動化概要
必要な要素として下記の点を満たしているものを考えました。
①単行本の作品ページのデータを取得し、特典について前回実行分と差分があるか判別する。差分は特典内容に対する更新のみであることを判別できるようにする。
②差分があった際に通知をする。(今回はデスクトップ通知とディスコード通知にしましたが、ラインとかメールとかも可能なようです。)
③上記①、②を数時間おきなどで定期実行する
③についてはSchedule文でも数時間おきに実行することは可能なようですが、今回はタスクスケジューラーを使って比較的簡単に済みましたのでそちらを使いました。というわけで①、②についてプログラムを作成しました。
・前提事項
下記のプログラムを使用する場合、Pythonの導入が必要になりますがそこから説明すると長くなりすぎてどうしようもないので割愛します。
ググれば出てくるものとは思いますが、私は初めてPythonを使ったときはこちらの本を参考にしました。Pythonの導入、エディタの導入、基本的な使い方からwebスクレイピングまで載っているので初心者の方には良いかもです。(某所のステマ)
次に、定期実行にするには実行場所として下記のようなものがあると思います。
①家のPCを起動し続ける
②Herokuなどクラウドを使う
③サーバーを借りる
私は①は電気代の問題と耐久面の不安、夜にうるさいなどの理由から避け、②のHerokuはCSVファイルの格納や指定がよくわからず、googleは金額計算のサイトが英語で読めずに怖かったため、③としてさくらのwindowsのVPSサーバーを使用しました。(レンタルサーバーではPythonが上手く動かない問題があったためVPSサーバーを使用)
・ソース
なお、今回はゲーマーズでの確認用です。抽出箇所が異なるため、htmlを確認するなどして店舗ごとに調整が必要になります。
import requests import difflib import datetime import os import re from discordwebhook import Discord from bs4 import BeautifulSoup from plyer import notification #ファイルの格納先 dir_path =r'E:\ドキュメント\surasura-python\tokuten' #前回取得ファイル file1_name = "gemazu1.csv" #今回取得ファイル file2_name = "gemazu2.csv" #店名を指定 tenmei="ゲーマーズ" #ここに対象のページのアドレスを入力 result = requests.get('****************') soup = BeautifulSoup(result.text,'html.parser') #スクレイピングの抽出対象を指定 html_list =soup.find_all(id=re.compile("tokuten")) ##ここから上は修正要 #今回分をgemazu2に保存し、前回と差分があれば報告してgemazu1を同内容で更新する #取得した内容をファイル2(今回分)に取得内容を記載 with open(file2_name,'w')as f: for html in html_list: okikae = html.get_text() naiyou = okikae.replace('\xa0','') f.write(naiyou) #パスを記載 file1_path = os.path.join(dir_path, file1_name) file2_path = os.path.join(dir_path, file2_name) #更新無しで初期化 kousin="nasi" #ファイル1があれば2と比較をする。なければ新規作成して終了。 if os.path.isfile(file1_path): file1 = open(file1_path) file2 = open(file2_path) #diffを定義 diff = difflib.Differ() #差分を抽出 output_diff = diff.compare(file1.readlines(), file2.readlines()) #差分箇所があれば更新ありフラグを立てる for data in output_diff : if data[0:1] in ['+', '-'] : kousin="ari" print(data) file1.close() file2.close() #ファイル1(前回分)に今回取得内容を記載 with open(file1_name,'w')as f: for html in html_list: okikae = html.get_text() naiyou = okikae.replace('\xa0','') f.write(naiyou) #デスクトップ通知とディスコード通知 if kousin == "ari": print(data) notification.notify( title = "ゆゆ式", message=tenmei+"特典更新あり", timeout=10 ) discord = Discord(url="*******************") discord.post(content=tenmei+"特典が更新されました。") else: print("なし")
・出力の想定
(1)基本的に各種作品ページは特典がある場合以下のように推移する。
①→②、②→③の場合にのみ通知を出力することとする。
①作品ページ作成時:この時点では特典情報の欄がないことが多い。
②特典種別掲載時:ここで、「クリアファイル」、「ブックカバー」など種別が表示される。ただし、特典画像は載っておらず「Now Printing」などが表示されていたりしている。
③特典画像掲載時:画像が掲載される。
(2)通知方法
外出時でも確認できるように更新の通知はディスコード通知でスマホにプッシュ通知が届くようにする。
・結果
ゆゆ式では確認できていませんが、他作品でテストしたところ動作は問題ありませんでした。特典部分が変わるとディスコードに通知が来るので家の外にいてもスマホで更新の確認ができそうです。サーバーで定期実行をすれば定期的に確認可能です。
これで次回以降は特典確認が楽にできますね。(まあ、もう公式告知があるのでほぼ不要なんですが…いい時代です。)
・課題
今後の課題点として以下のような点があります。
・抽出箇所の選定問題
html_list =soup.find_all(id=re.compile("tokuten"))の箇所になりますが、サイトごとに構成が違うため、メロンブックスやとらのあななど店舗ごとに抽出箇所を調べて変更する必要が出てくる。→各店舗分の作成が必要
また、サイトが改修された場合も抽出箇所を変えないといけない場合もある。
→巻が変わるごとに正常に動作するか確認が必要
・そもそも特典のある店舗がどこなのかという問題
正直わからないので前巻で出た店舗を調べるなり、他作品を参考に推測で進めるしかない。
・外出時の確認の際に結果的にサイトを見に行く必要がある
上記ソースでは画像が抽出されていないので、どういった画像なのか確認するにはそのページを見に行かなくてはならない。画像が貼られてる場合はその画像を貼れるようにするように調整したい。
・活用法について
きらら公式で告知されるのでだいたい不要なんですが、ざっと思いつく限りでは以下があります。
・メロンブックスでは過去に連動特典として他の巻と一緒に買うと特典が付く場合があった。公式で告知されないそういった更新をを読み取ることができる。
・公式告知より早く特典内容を知ることができる。
などでしょうか。
・まとめ
ゆゆ式の特典確認の自動化としては一定程度可能になりましたが、機能面で足りていない部分や各店舗対応などがまだ必要になりそうです。
また、可能であれば今後考察に生かせるプログラムかなにかを作れたらと思いました。(まあ、Pythonよくわからんので難しそうですが…)
↓手動だった頃の記録
『ゆゆ式』9巻 店舗別特典まとめ - 茶番のアレ https://t.co/AhErdvqXue 描き下ろし以外もまとめてくれてる方がいました!
— 三上小又@ゆゆ式12巻発売!! きららファンタジアやってるよ。 (@mikamikomata) 2017年8月23日